When training neural ODEs, many different model architectures and training procedures are available, all with different effects on the quality of the resulting model. Furthermore, other parameters such as the length of the ODE solutions used for training can also affect the quality of the trained model. For example, on the Kuramoto-Sivashinsky equation the length of the trajectories used for training can make the difference between a model that produces accurate predictions and a model that produces very poor results. This is illustrated in the figures below.
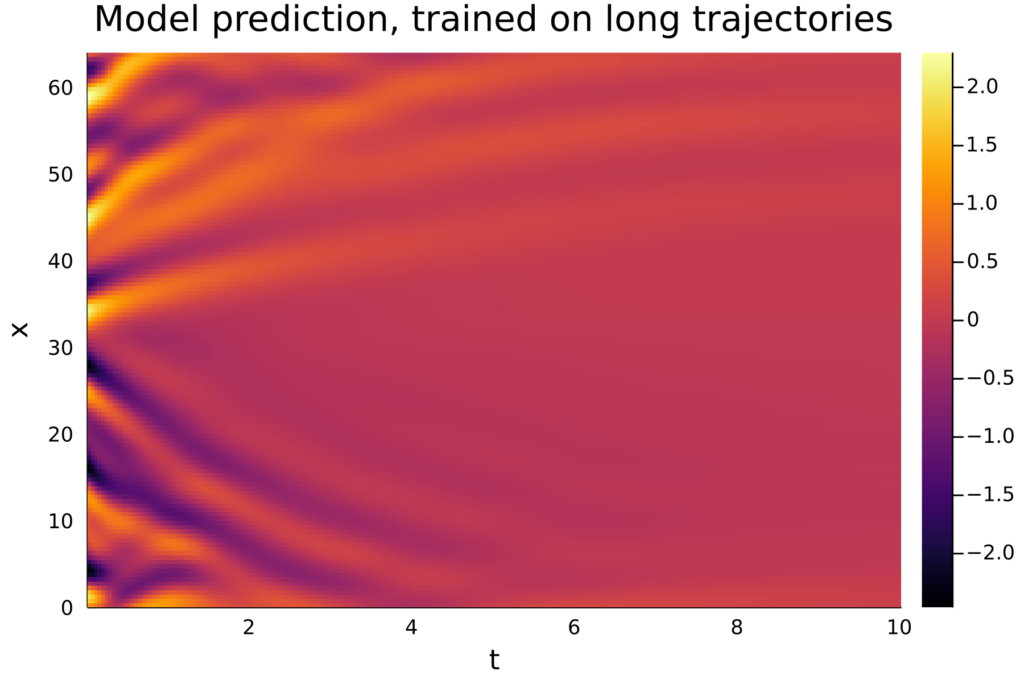
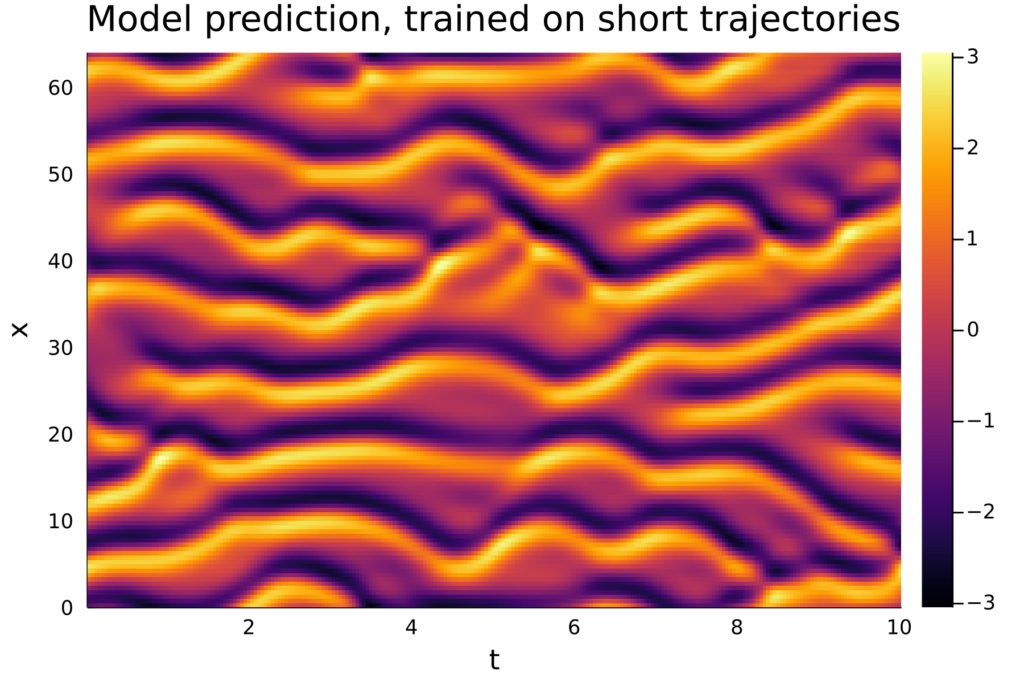
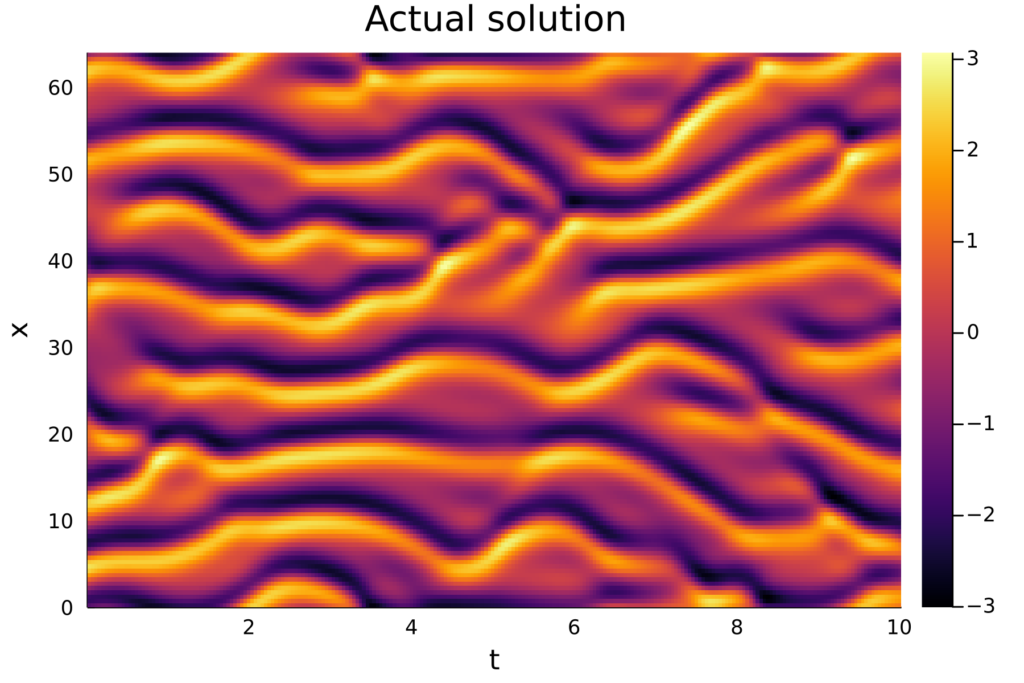
In his thesis, Hugo Melchers trained a variety of different ML models in a number of different methods, so that general recommendations can be made regarding model architectures, training procedures, and more.